PatANN - Pattern-Aware Vector Database and ANN Framework #
Overview #
PatANN is a pattern-aware, massively parallel, and distributed vector search framework designed for scalable and efficient nearest neighbor search, operating both in-memory and on-disk.
Unlike conventional ANN algorithms, PatANN leverages macro and micro patterns within vectors to drastically reduce the search space before performing costly distance computations, resulting in unprecedented performance advantages. As shown in our benchmarks (Figure 1), PatANN consistently outperforms leading ANN libraries—including HNSW (hnswlib), Google ScaNN, and Facebook FAISS variants – throughout the entire recall-throughput spectrum. PatANN also demonstrates superior scaling as dataset size increases, with efficiency gains becoming more pronounced at billion scale.
PatANN is architected from the ground up for native asynchronous and parallel execution – the first among ANN systems – enabling billion-scale search by maximizing parallelism throughout the entire pipeline – a fundamental advantage over synchronous designs like FAISS, ScaNN, HNSW, and commercial databases based on them. PatANN is also NUMA-aware to ensure efficient scaling on modern multi-socket CPUs by maximizing local parallelism and minimizing remote memory access.
A technical overview of the algorithm, based on our upcoming research paper, is available in the Algorithms section. The full paper detailing PatANN’s design and performance characteristics will be published soon.
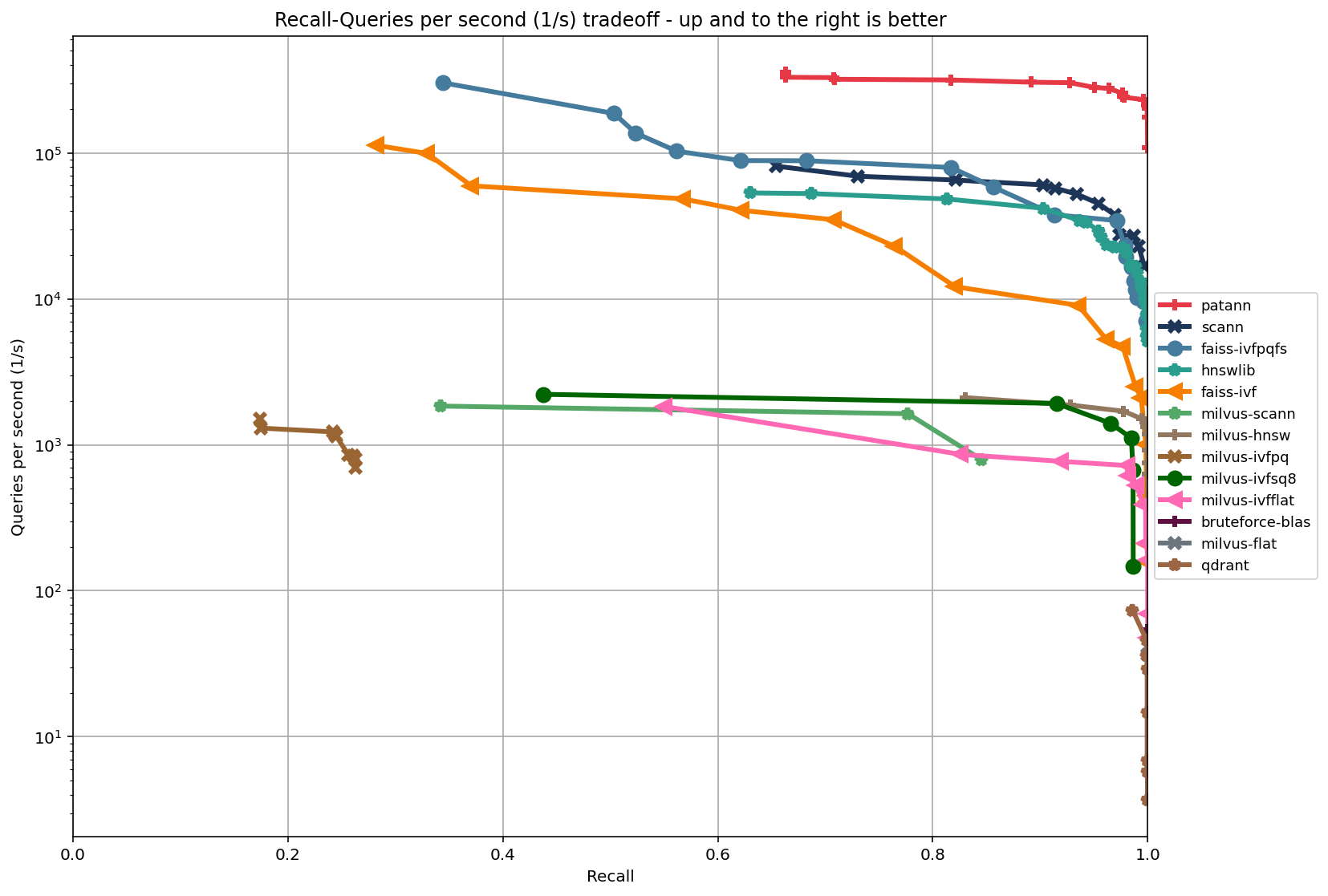
These benchmarks were conducted using the industry-standard ann-benchmarks suite on the SIFT-128-Euclidean dataset. Complete benchmark results can be found on the Benchmarks section of the site.
PatANN Technical Deep Dive #
We recommend watching this technical analysis for a comprehensive understanding of vector database architectural limitations and how PatANN addresses these challenges for massive scalability.
For optimal viewing of technical analysis and graphs, set video quality to 1080p and view in fullscreen mode.
Supported Platforms #
PatANN runs seamlessly across both desktop (Linux, macOS, Windows) and mobile (Android, iOS) platforms. Refer to the installation guide and code examples for platform-specific usage instructions.
With its fully asynchronous architecture and on-disk indexing support, PatANN delivers efficient performance even in resource-constrained environments like mobile devices. The Examples section includes code for both asynchronous and synchronous modes on desktop and mobile platforms.
Key Innovations: Redefining Vector Search Architecture #
While the Pattern-Aware algorithm forms the core strength enabling PatANN to achieve high recall at high QPS in high-dimensional data, its architecture has been meticulously designed from the ground up to address fundamental limitations across all existing ANN implementations.
1. Fully Asynchronous, Parallel Execution #
Most existing ANN libraries—including FAISS, ScaNN, HNSWlib, and commercial variants—are fundamentally synchronous. While users can achieve query-level parallelism using thread pools or async I/O wrappers, the underlying algorithms remain inherently single-threaded, unable to execute a single query concurrently. Each thread typically handles one query at a time, with concurrency constrained by thread-level isolation.
Some commercial databases provide async APIs at the network layer (via gRPC or REST), but their underlying ANN execution remains synchronous at the algorithm level.
PatANN is asynchronous by design. It decomposes queries for parallel execution across multiple threads, enabling lock-free, non-blocking search paths. This allows a single query to leverage multiple cores simultaneously—an architectural approach that is, to date, unique among ANN implementations.
2. In-Memory and On-Disk Indexing #
Most ANN libraries assume that the entire index must reside in RAM, severely limiting scalability for large datasets or memory-constrained environments.
- FAISS: Offers memory mapping but requires substantial RAM for query-time structures. On-disk querying remains experimental.
- HNSWlib, ScaNN: Purely in-memory architectures with no native mmap or disk support.
- Annoy: Supports lazy loading from disk but suffers significant performance degradation without proper caching.
- Milvus, Weaviate, etc.: Claim disk support but typically preload most of the index into RAM. Disk I/O is largely limited to metadata persistence or checkpointing rather than runtime operations.
PatANN supports true hybrid execution. It uses OS-level memory management features, including HugePages (Linux), Large Pages (Windows), and Super Pages (macOS) for efficient memory access. When these page optimizations are unavailable, PatANN employs its own disk caching mechanism. This architecture delivers consistent performance even under severe memory constraints and enables support for larger datasets while maintaining fast cold starts.
3. Elastic Capacity #
Most ANN systems—including HNSW-based and commercial solutions—require fixed-size indexing with no native support for dynamic growth. These systems force users to specify capacity upfront, leading to two critical inefficiencies:
- Wasted Resources: Operators must over-allocate memory to anticipate future growth, leaving capacity underutilized until the data scales up.
- Growth Constraints: If actual demand exceeds initial estimates, the entire index must be rebuilt from scratch, causing downtime and operational overhead.
PatANN eliminates these limitations with elastic scaling. Initialize with capacity for hundreds of thousands of nodes while planning for billions—no preallocation, restarts, or reindexing required. PatANN adapts dynamically as dataset grows, ensuring resource efficiency without manual intervention.
4. Hardware Acceleration #
PatANN leverages SIMD and vector extensions extensively to accelerate distance computations and core operations across x86 and ARM architectures:
- x86: SSE4, AVX2, AVX-512 (AMX is planned)
- ARM: NEON, SVE (SVE2 support forthcoming)
This is NOT optional – PatANN requires SIMD-capable CPUs for the highly parallel execution necessary to achieve high recall at high throughput. By design, PatANN excludes CPUs without SIMD capabilities, eliminating low-performing fallback code paths that have no place in modern infrastructure.
5. Non-Uniform Memory Access (NUMA) Optimization (Linux only) #
PatANN is NUMA-aware by default. Modern inference and search servers commonly feature 2–4 CPU sockets with high core counts, where memory access latency varies significantly based on NUMA node topology. While many ANN libraries either ignore NUMA layout or require complex manual tuning, PatANN keeps compute and memory co-located within the same NUMA nodes. This approach improves cache efficiency and reduces cross-node traffic, providing consistent performance under demanding conditions of high QPS and low-latency requirements.
6. Non-Disruptive Filtering #
Most ANN systems implement filtering through a filtering hook injected into the core search algorithm. This design pattern—seen in graph-based algorithms like HNSW and others—introduces two critical issues:
- Performance overhead: The hook is invoked for every visited node during graph traversal, making searches significantly slower, particularly in high-QPS environments where latency is critical.
- Disjointed results: Filtering during graph traversal disrupts natural neighborhood continuity, often leading to suboptimal recall and unpredictable result quality as the search follows suboptimal paths.
While some systems attempt to mitigate these issues by adding alternate graph paths or fallback candidates, these approaches introduce structural complexity without fully addressing the fundamental problem.
PatANN takes a different approach. Instead of filtering inline, PatANN applies filtering in a dedicated refinement phase after candidate generation. This avoids the overhead of per-node logic during traversal and preserves the integrity of the result set. The refinement process is designed for high performance and maintains structural consistency even under complex filtering criteria.
PatANN addresses core limitations in existing vector search systems and achieves unprecedented performance at scale through a fundamentally redesigned architecture. All features—from NUMA awareness to asynchronous execution, hybrid memory management, and elastic scaling—are accessible through an easy-to-use intuitive API, simplifying implementation while delivering substantial performance advantages.
Status #
Beta Version: Currently in Beta.
Contact #
Technical Support #
For technical questions, please:
- Post on Stack Overflow with the tag #patann
- Open an issue in PatANN GitHub repository
Other #
For other questions or collaboration, please email: support@mesibo.com